Publications
2025
-
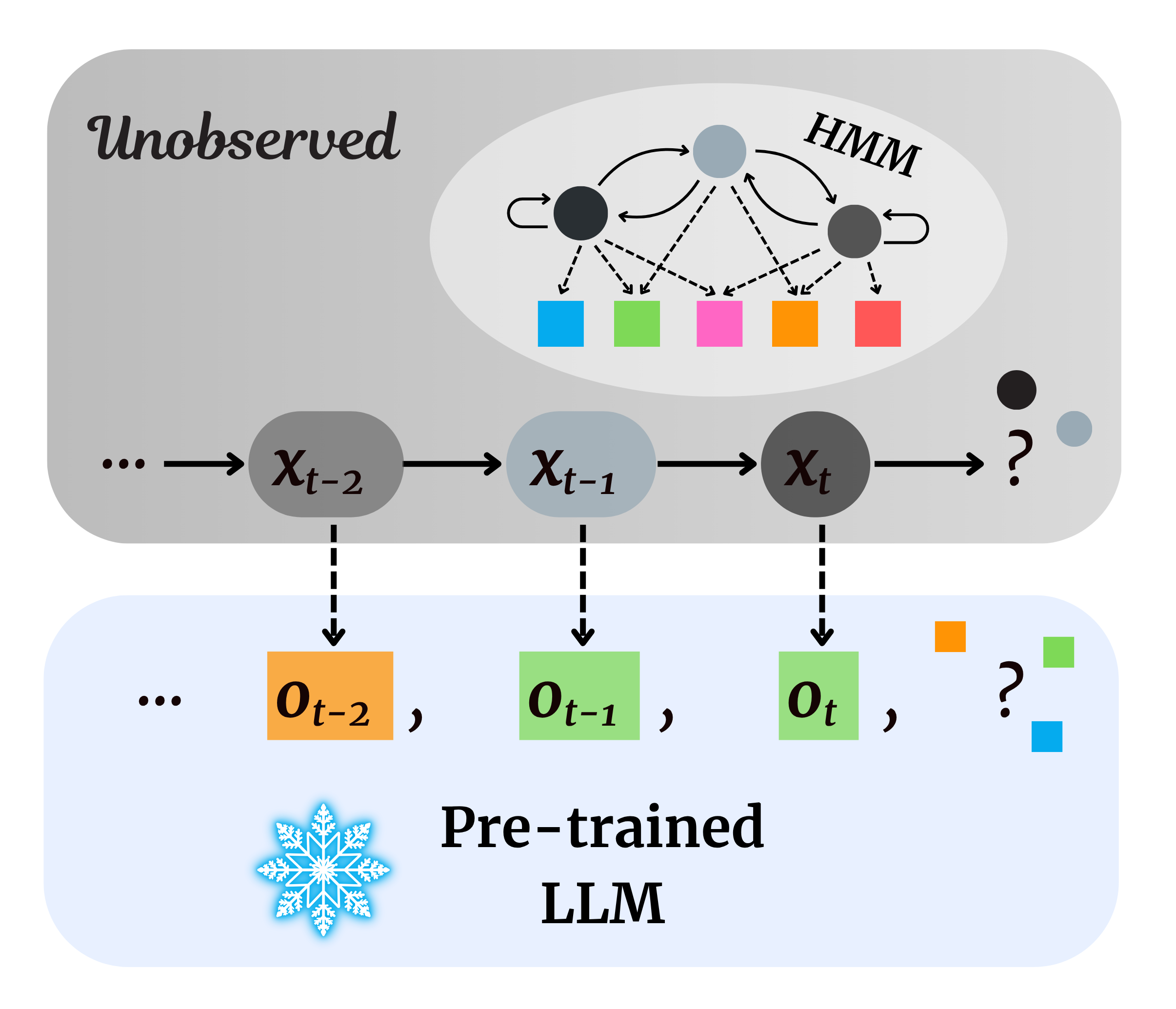 Pre-trained Large Language Models Learn Hidden Markov Models In-contextYijia Dai, Zhaolin Gao, Yahya Satter, and 2 more authors2025
Pre-trained Large Language Models Learn Hidden Markov Models In-contextYijia Dai, Zhaolin Gao, Yahya Satter, and 2 more authors2025Hidden Markov Models (HMMs) are foundational tools for modeling sequential data with latent Markovian structure, yet fitting them to real-world data remains computationally challenging. In this work, we show that pre-trained large language models (LLMs) can effectively model data generated by HMMs via in-context learning (ICL)–their ability to infer patterns from examples within a prompt. On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum. We uncover novel scaling trends influenced by HMM properties, and offer theoretical conjectures for these empirical observations. We also provide practical guidelines for scientists on using ICL as a diagnostic tool for complex data. On real-world animal decision-making tasks, ICL achieves competitive performance with models designed by human experts. To our knowledge, this is the first demonstration that ICL can learn and predict HMM-generated sequences–an advance that deepens our understanding of in-context learning in LLMs and establishes its potential as a powerful tool for uncovering hidden structure in complex scientific data.

2024
-
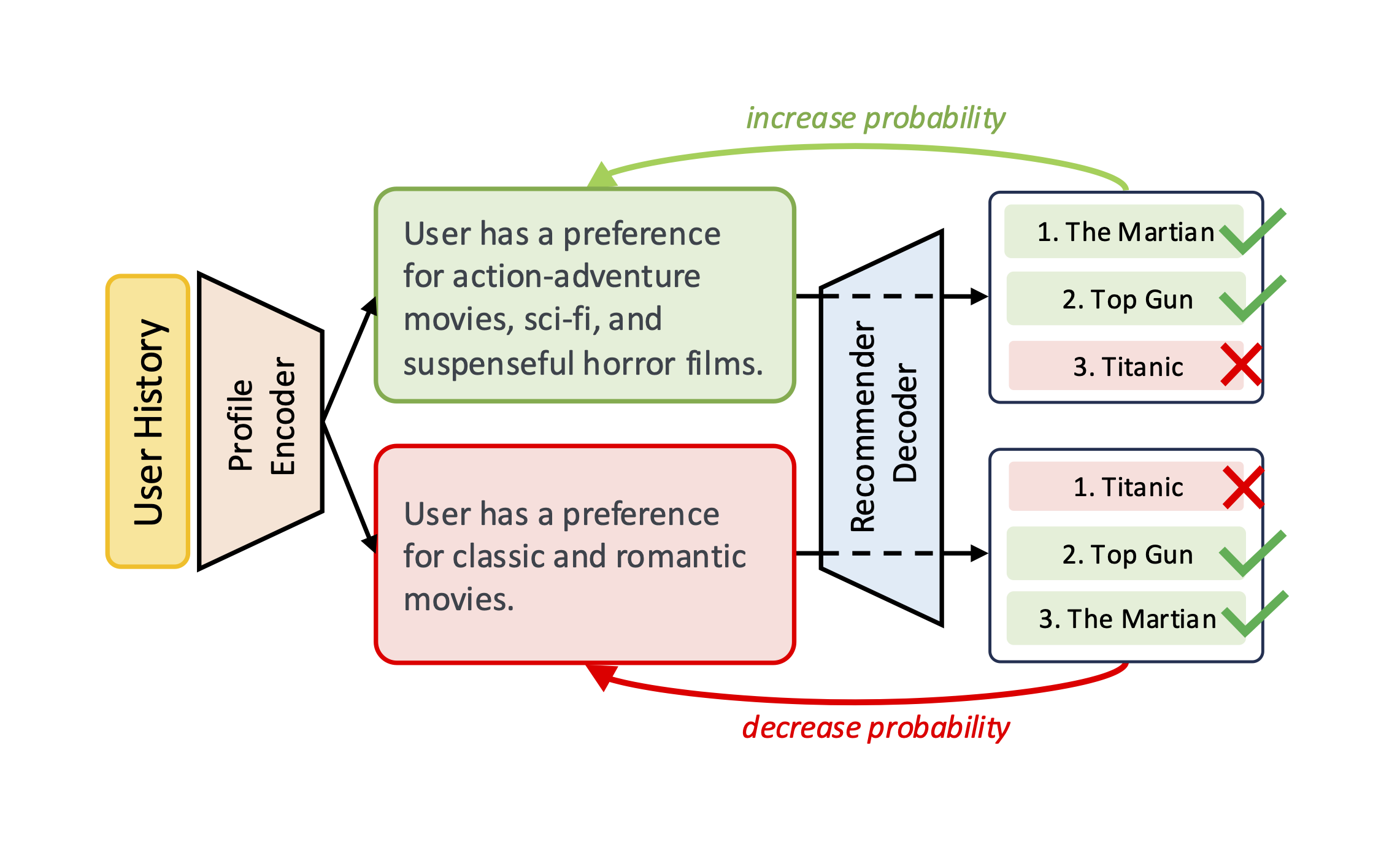 End-to-end Training for Recommendation with Language-based User ProfilesZhaolin Gao, Joyce Zhou, Yijia Dai, and 1 more author2024
End-to-end Training for Recommendation with Language-based User ProfilesZhaolin Gao, Joyce Zhou, Yijia Dai, and 1 more author2024There is a growing interest in natural language-based user profiles for recommender systems, which aims to enhance transparency and scrutability compared with embedding-based methods. Existing studies primarily generate these profiles using zero-shot inference from large language models (LLMs), but their quality remains insufficient, leading to suboptimal recommendation performance. In this paper, we introduce LangPTune, the first end-to-end training framework to optimize LLM-generated user profiles. Our method significantly outperforms zero-shot approaches by explicitly training the LLM for the recommendation objective. Through extensive evaluations across diverse training configurations and benchmarks, we demonstrate that LangPTune not only surpasses zero-shot baselines but also matches the performance of state-of-the-art embedding-based methods. Finally, we investigate whether the training procedure preserves the interpretability of these profiles compared to zero-shot inference through both GPT-4 simulations and crowdworker user studies.
-
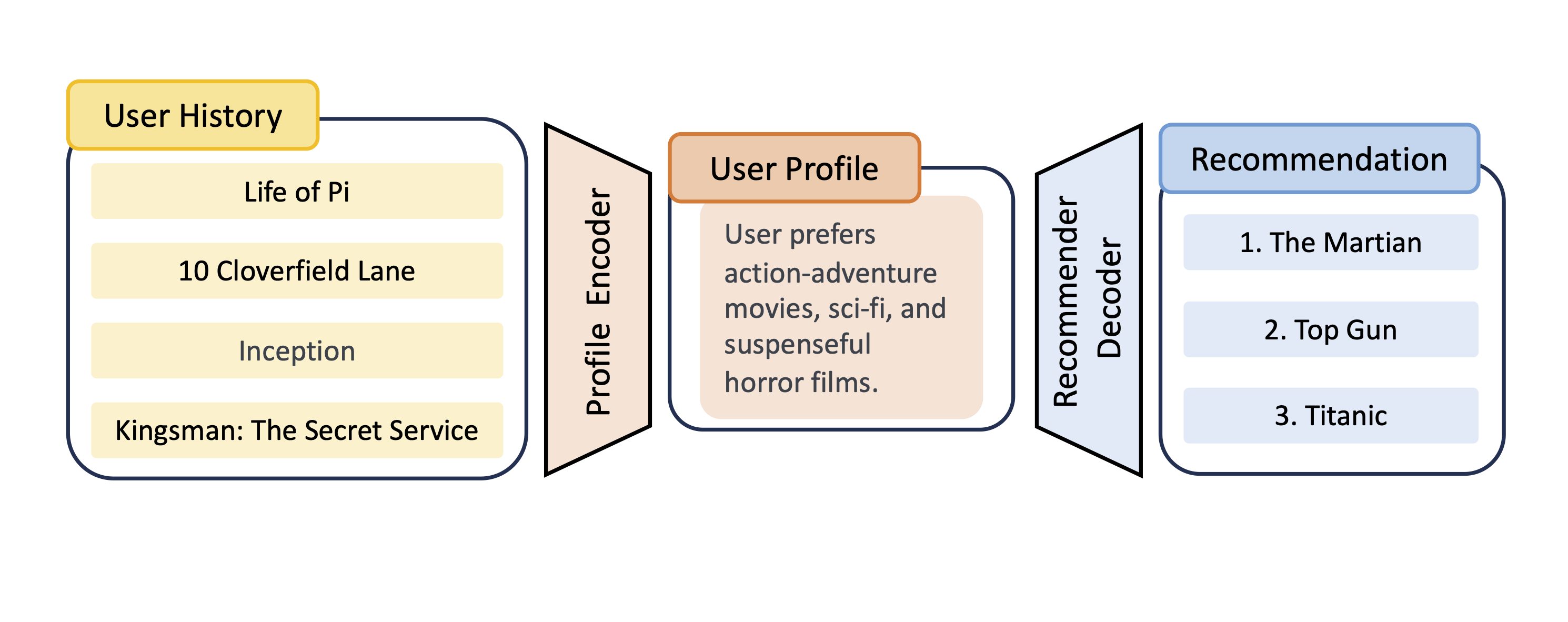 Language-Based User Profiles for RecommendationJoyce Zhou, Yijia Dai, and Thorsten Joachims2024
Language-Based User Profiles for RecommendationJoyce Zhou, Yijia Dai, and Thorsten Joachims2024Most conventional recommendation methods (e.g., matrix factorization) represent user profiles as high-dimensional vectors. Unfortunately, these vectors lack interpretability and steerability, and often perform poorly in cold-start settings. To address these shortcomings, we explore the use of user profiles that are represented as human-readable text. We propose the Language-based Factorization Model (LFM), which is essentially an encoder/decoder model where both the encoder and the decoder are large language models (LLMs). The encoder LLM generates a compact natural-language profile of the user’s interests from the user’s rating history. The decoder LLM uses this summary profile to complete predictive downstream tasks. We evaluate our LFM approach on the MovieLens dataset, comparing it against matrix factorization and an LLM model that directly predicts from the user’s rating history. In cold-start settings, we find that our method can have higher accuracy than matrix factorization. Furthermore, we find that generating a compact and human-readable summary often performs comparably with or better than direct LLM prediction, while enjoying better interpretability and shorter model input length. Our results motivate a number of future research directions and potential improvements.


2023
-
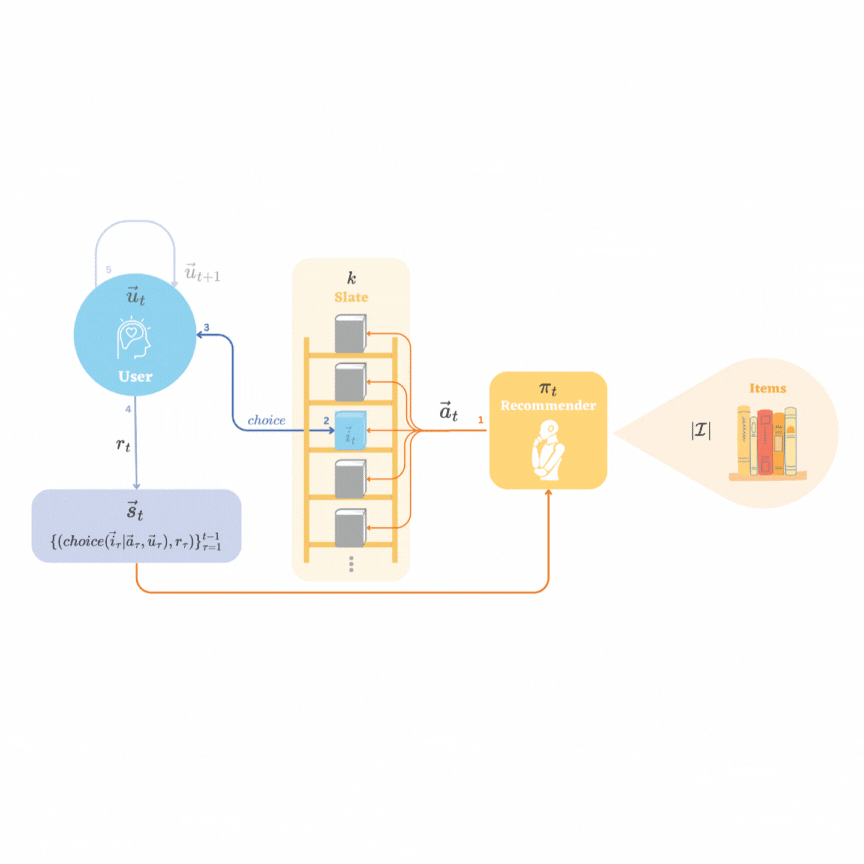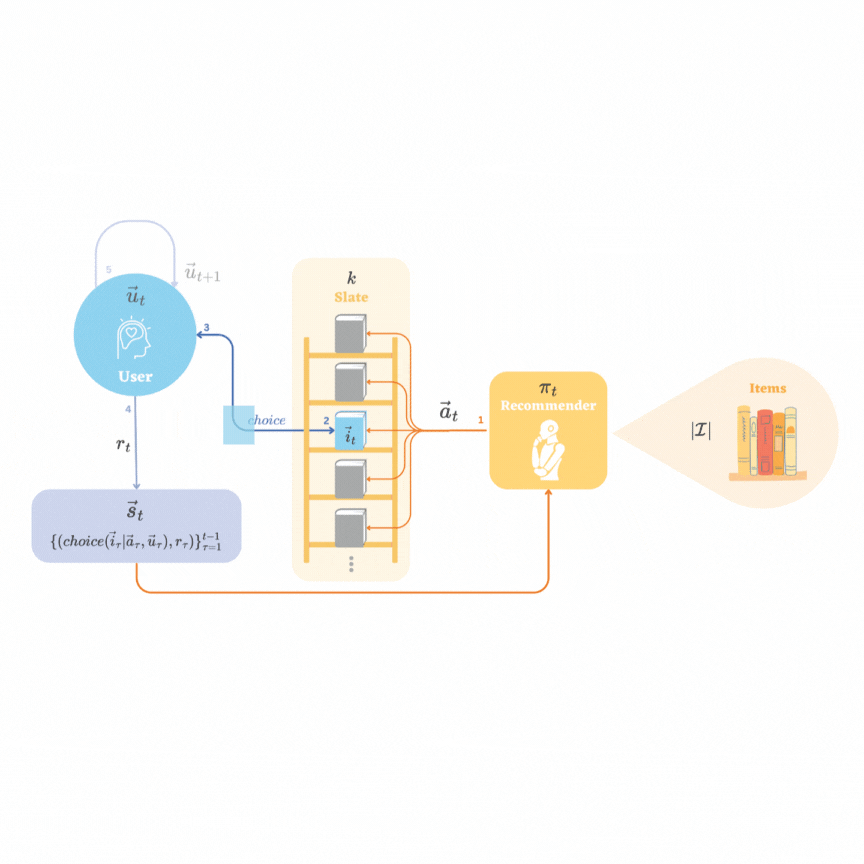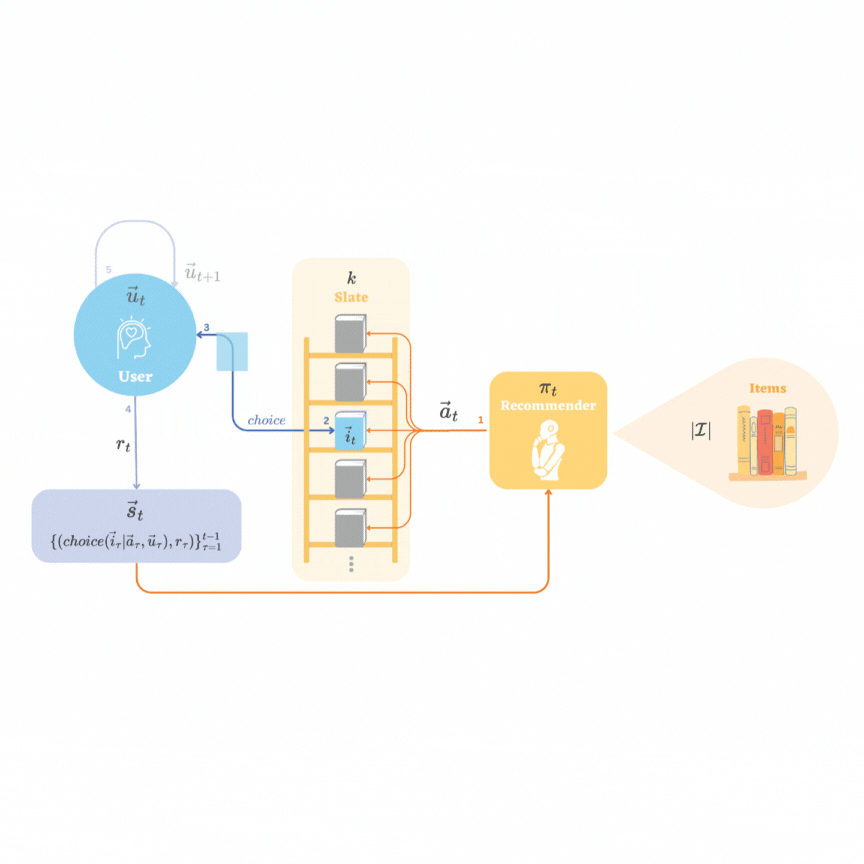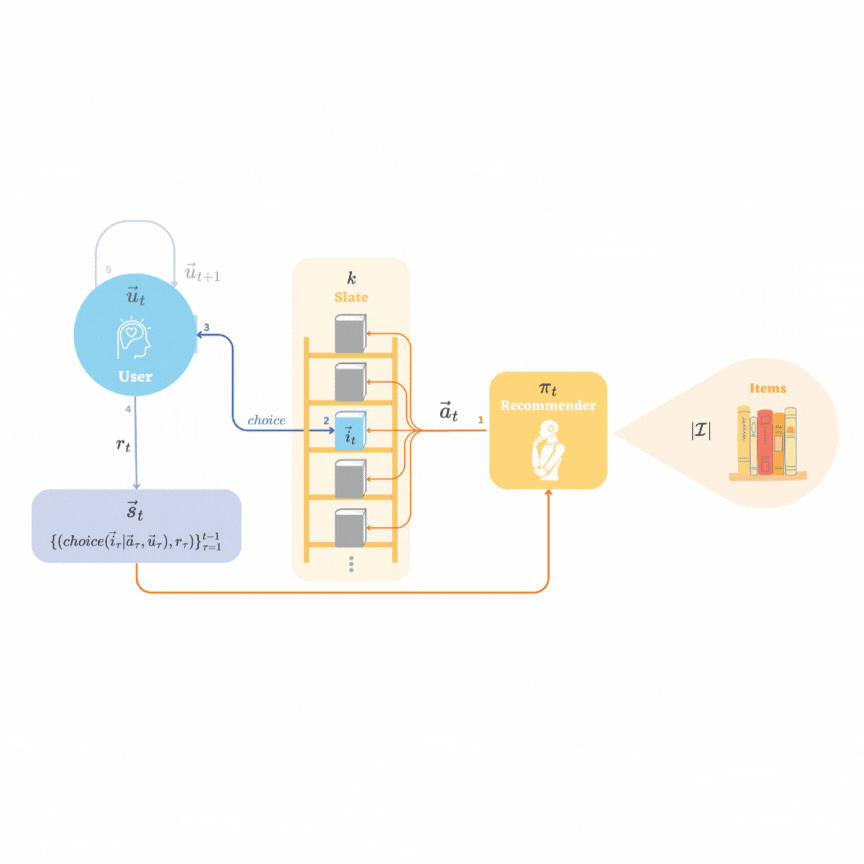 Representation Learning in Low-rank Slate-based Recommender SystemsYijia Dai, and Wen Sun2023
Representation Learning in Low-rank Slate-based Recommender SystemsYijia Dai, and Wen Sun2023Reinforcement learning (RL) in recommendation systems offers the potential to optimize recommendations for long-term user engagement. However, the environment often involves large state and action spaces, which makes it hard to efficiently learn and explore. In this work, we propose a sample-efficient representation learning algorithm, using the standard slate recommendation setup, to treat this as an online RL problem with low-rank Markov decision processes (MDPs). We also construct the recommender simulation environment with the proposed setup and sampling method.
-
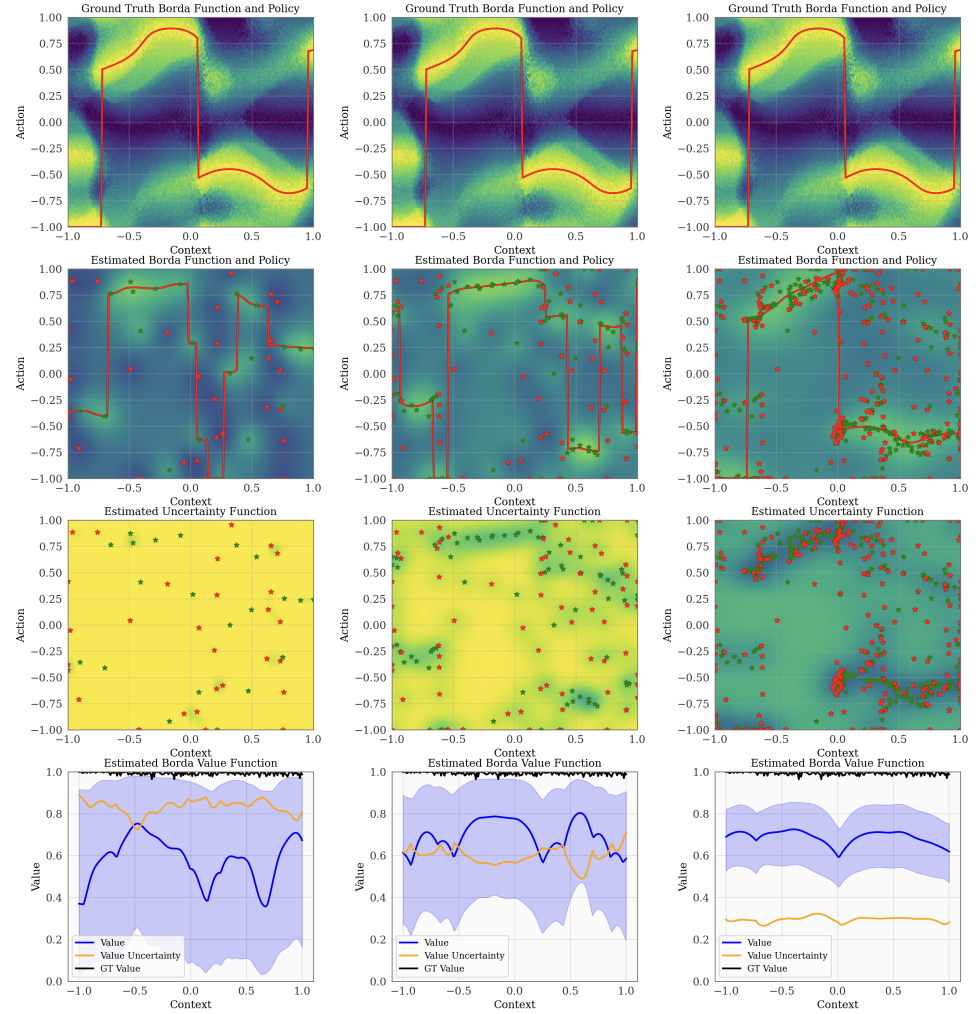 Sample Efficient Reinforcement Learning from Human Feedback via Active ExplorationViraj Mehta, Vikramjeet Das, Ojash Neopane, and 4 more authors2023
Sample Efficient Reinforcement Learning from Human Feedback via Active ExplorationViraj Mehta, Vikramjeet Das, Ojash Neopane, and 4 more authors2023Preference-based feedback is important for many applications in reinforcement learning where direct evaluation of a reward function is not feasible. A notable recent example arises in reinforcement learning from human feedback (RLHF) on large language models. For many applications of RLHF, the cost of acquiring the human feedback can be substantial. In this work, we take advantage of the fact that one can often choose contexts at which to obtain human feedback in order to most efficiently identify a good policy, and formalize this as an offline contextual dueling bandit problem. We give an upper-confidence-bound style algorithm for this problem and prove a polynomial worst-case regret bound. We then provide empirical confirmation in a synthetic setting that our approach outperforms existing methods. After, we extend the setting and methodology for practical use in RLHF training of large language models. Here, our method is able to reach better performance with fewer samples of human preferences than multiple baselines on three real-world datasets.


2019
-
 Growth Mechanisms and the Effects of Deposition Parameters on the Structure and Properties of High Entropy Film by Magnetron SputteringYanxia Liang, Peipei Wang, Yufei Wang, and 9 more authorsMaterials, 2019
Growth Mechanisms and the Effects of Deposition Parameters on the Structure and Properties of High Entropy Film by Magnetron SputteringYanxia Liang, Peipei Wang, Yufei Wang, and 9 more authorsMaterials, 2019Despite intense research on high entropy films, the mechanism of film growth and the influence of key factors remain incompletely understood. In this study, high entropy films consisting of five elements (FeCoNiCrAl) with columnar and nanometer-scale grains were prepared by magnetron sputtering. The high entropy film growth mechanism, including the formation of the amorphous domain, equiaxial nanocrystalline structure and columnar crystal was clarified by analyzing the microstructure in detail. Besides, the impacts of the important deposition parameters including the substrate temperature, the powder loaded in the target, and the crystal orientation of the substrate on the grain size and morphology, phase structure, crystallinity and elemental uniformity were revealed. The mechanical properties of high entropy films with various microstructure features were investigated by nanoindentation. With the optimized grain size and microstructure, the film deposited at 350 °C using a power of 100 W exhibits the highest hardness of 11.09 GPa. Our findings not only help understanding the mechanisms during the high entropy film deposition, but also provide guidance in manufacturing other novel high entropy films.
